- Published on
Aurora - Global Database
Overview
As part of this blog, we will be discussing the most suitable AWS solution for relational database while we consider these usecases:
- Multi-region read replication to support faster reads for all regions to support read locally and write globally.
- Low maintenance in terms of backup, fast restores and scaling for dynamic read loads.
- Automatic fallback if the primary instance fails
- High throughput and performance.
RDS VS Aurora
Amazon Aurora
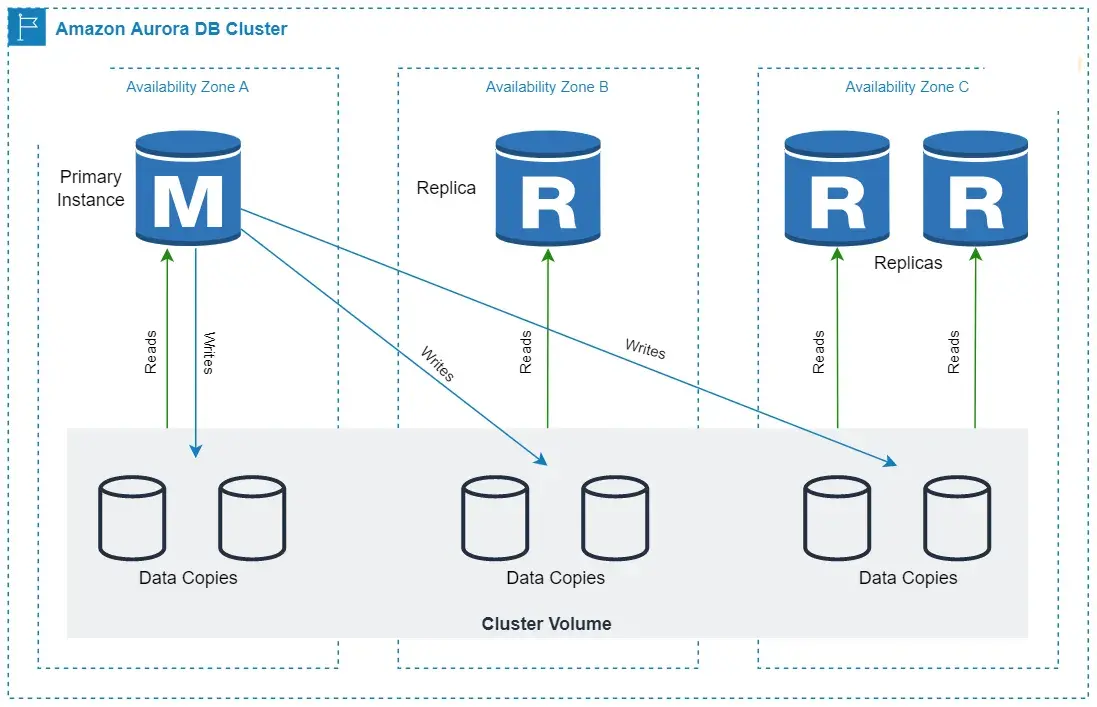
Amazon Aurora is a fully managed MySQL- and PostgreSQL-compatible relational database built for the cloud that combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open source databases.
Amazon RDS
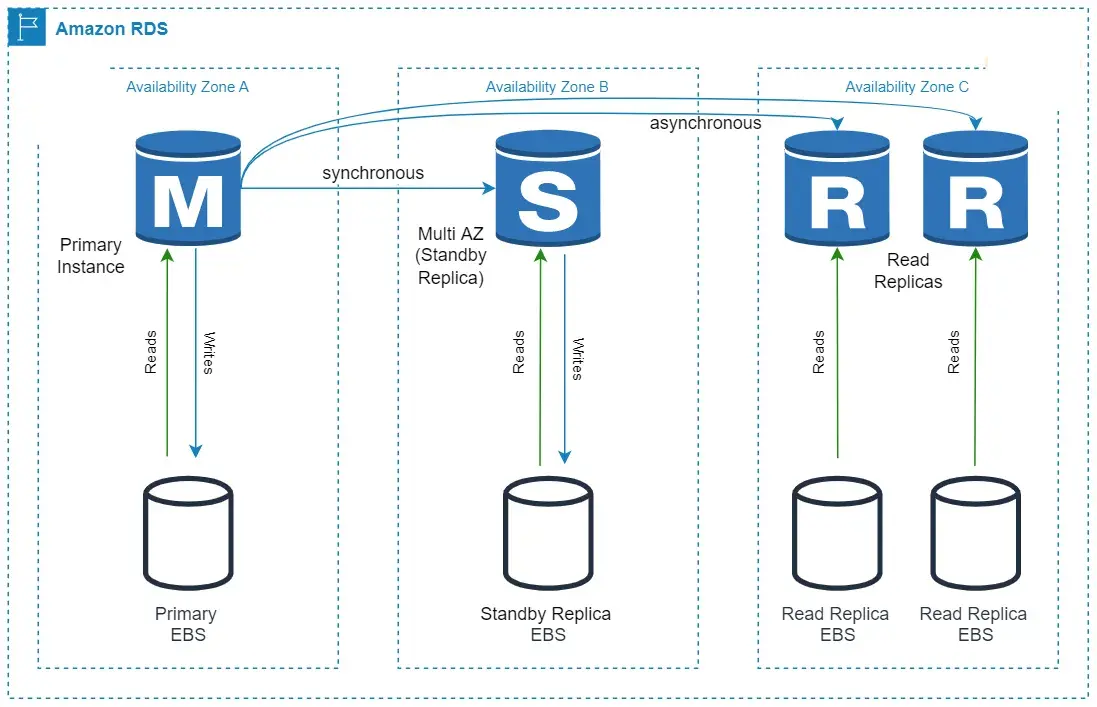
Amazon RDS (Relational Database Service) is a managed SQL database service a relational database in cloud which makes it easy to provision, setup, patching, and backups. It supports Aurora, MySQL, PostgreSQL, MariaDB, Microsoft SQL Server, and Oracle database engines.
Key Differences: Amazon Aurora vs Amazon RDS
Architecture Design (Aurora > RDS)
RDS architecture is similar to installing database engine on Amazon EC2 manually but leaving the provisioning and maintenance to AWS. RDS provides many features like automatic failover, backups, etc. RDS use Amazon EBS volumes for database and log storage. To achieve reliability, you need to enable the Multi-AZ feature on your RDS instance and replicate it synchronously to a standby replica in another Availability Zone. Aurora database storage is reliable and fault-tolerant by design. Aurora’s database storage is separate from the instances. In Aurora, data has 6 copies (as 10GB chunks distributed) to three Availability Zones. Hence, even if you have only one Aurora instance, your data will still have 6 copies.
Performance (Aurora > RDS)
RDS uses SSDs storage for better I/O throughput performance. You can choose between two SSD-backed storage options, that is, one that is optimized for high-performance OLTP applications and another one for cost-effective general-purpose use. Aurora gives two times throughput performance provided by PostgreSQL or five times the throughput provided by standard MySQL running on similar hardware. (https://aws.amazon.com/rds/aurora/features/) Aurora’s performance is higher and more consistent. Aurora writes logs directly to the storage without keeping log buffers. The replication to the replicas is asynchronous and for only cached data. Because the replicas also share the same storage cluster, the replica lag is small and consistent over time. Due to its unique storage design, Aurora’s performance stays consistent when the load increases.
Database Engine Support (RDS > Aurora)
RDS is compatible with MySQL, PostgreSQL, MariaDB, Microsoft SQL Server, and Oracle. Aurora is compatible with PostgreSQL and MySQL. It means you can run your existing database tools and applications on both without any modifications.
Availability and Durability (Aurora > RDS)
Aurora offers higher availability and better durability than RDS, due to its unique storage model, and ability to perform continuous backups and restore with a very low RPO (recovery point objective). In Aurora, data is durable by design. You always have multiple copies of your data. Every Aurora cluster has six storage nodes, spread across three AZs, even if you have just one compute node. In RDS, you have to max out your read replicas for this level of durability.
Resiliency (Aurora > RDS)
Aurora is more resilient than RDS because of its architectural design. It has a fast recovery from failures. If a compute node crashes, Aurora can recover quickly. It can start new read replicas with minimal lag, and if the writer fails, another replica can be promoted to take over without waiting for the other nodes to reach consensus. All the shared state is in the data nodes, so failed nodes can be replaced almost immediately.
Storage (Aurora ~ RDS)
RDS storage auto-scaling automatically scales storage capacity up to 64 TiB (except SQL Server’s 16 TiB) in response to growing database workloads, with zero downtime. With RDS Storage Auto Scaling, you simply set your desired maximum storage limit, and Auto Scaling takes care of the rest. Aurora automatically increases storage from a minimum of 10 GB to a maximum of 128 TiB. This is done in increments of 10 GB without any impact on the database performance. You are not required to provide the storage in advance.
Scalability (Aurora > RDS)
Vertical Scaling: Both, Aurora and RDS, allow you to scale the memory and compute resources up and down, to a maximum of 244 GiB of RAM and 32 vCPUs. Scaling operations can be done within a few clicks. Dynamic Scaling: Aurora Auto Scaling dynamically adjusts the number of Aurora Replicas provisioned for an Aurora DB cluster using single-master replication. It enables your Aurora DB cluster to handle sudden increases in connectivity or workload. When the connectivity or workload decreases, It removes unnecessary Aurora Replicas, so that you don’t pay for unused provisioned DB instances. RDS does not support such Auto Scaling.
Replication (Aurora > RDS)
RDS allows you to provision up to 5 replicas, and the process of replication is slower compared to Aurora. Aurora allows you to provision up to 15 replicas, and the replication is done in milliseconds. Aurora scales faster because it can add new read replicas quickly. Because replicas all use the shared storage volume, a new replica can serve queries almost immediately. It doesn’t have to wait to replicate data from the other nodes. Aurora does some asynchronous cache replication between nodes, but nothing synchronous. This reduces the inter-node I/O, which means Aurora can have more replicas.
Failover (Aurora > RDS)
In RDS, Failover to read replica is done manually, which could lead to data loss. You can use Multi-AZ (Standby instance) feature for automatic failover, and to prevent downtime and data loss. In Aurora, Failover to read replica is done automatically to prevent data loss. Failover time is faster on Aurora.
Cluster Endpoints (Aurora > RDS)
In RDS, there is a cluster endpoint that you use for your write queries. It is the DNS endpoint pointing to your current master db instance. During a failover, RDS routes this endpoint to the new master by a simple DNS change. However, for read replicas, you have to balance the load in your application using the instance endpoints. RDS does not provide a load balancer for read replicas. In Aurora, you still use cluster endpoint for your write queries. It also provides a reader endpoint acting as a load balancer for your read replicas. So you can use this endpoint for your read queries. In the case of a failover, one of the read replicas become master and is removed from this reader set.
Backup (Aurora > RDS)
RDS creates and saves automated backups of your DB instance during the backup window of your DB instance. RDS creates a storage volume snapshot of your DB instance, backing up the entire DB instance and not just individual databases according to the backup retention period that you specify. If necessary, you can recover your database to any point in time during the backup retention period. While the snapshot is being taken, storage I/O may be interrupted while data is copied, affecting database performance. Aurora backs up your cluster volume automatically and retains restored data for the length of the backup retention period. Aurora backups are continuous and incremental so you can quickly restore to any point within the backup retention period. No performance impact or interruption of database service occurs as backup data is being written. For both, Backups are stored in Amazon S3.
Pricing (RDS > Aurora)
Aurora is more expensive than RDS for the same workloads. Aurora pricing is mainly based on instance size and storage is billed according to actual usage.
Amazon Aurora Features
We would use the below features which are only present in Aurora:
Aurora Serverless
Aurora Serverless lets you run Aurora without having to guess how many compute nodes you need. It automatically starts and stops nodes to match the needs of your application. It scales up to meet a spike in demand and scales down when things are quiet. The data remains in the shared storage volume, independent of any scaling.
Aurora Global Database
Aurora Global Database is designed for globally distributed applications, allowing a single Amazon Aurora database to span multiple AWS regions. It replicates your data with no impact on database performance, enables fast local reads with low latency in each region, and provides disaster recovery from region-wide outages.
Other features
- Aurora DB Backtrack
- Aurora DB Activity Monitoring
Summary
Aurora’s unique architecture gives you more durability, scalability, resiliency, and performance when compared to RDS. Although there is a small increase in cost, it is recommend using Aurora for enterprise-level applications. For our native high availability solution and/or read-intensive workload, with multi Region support Aurora is a perfect solution.
Aurora Setup
Multi Region Setup
First, two different Route 53 CNAME records are configured and associated with the reader and writer Aurora database endpoints. The consuming application uses those endpoints to call the Aurora database, depending on the read or write operation. The application is deployed in multi-region (primary and secondary regions). Aurora Global Database uses a built-in replication feature to replicate data from the primary Region to the secondary region. The secondary region’s DB instance is read-only and can be used to scale the read operations for your applications by connecting to the reader endpoint of the cluster.
Route 53 and Global Database Endpoint
Using Route 53 service to manage our database endpoints, and after failover we don't have to change the connection string. After the failover, we simply update the CNAME record to the new writer in the secondary region and applications will never have to make any connection string changes and will continue to talk to the same road 53 DNS endpoint
Planned fail over process
During planned fail over (eg: disaster recovery drill or relocate primary database to a new region), since the database clusters in all regions are healthy, the primary cluster will be switched to one of the secondary regions and the current primary cluster will be changed to a secondary cluster with no active writer instance. All Aurora Global Database configuration will be retained. There will not be any data loss during this switch over. The following operations will be executed during a planned failover:
- Stop write operations to the primary database
- Replicate all changes from primary cluster to all secondary clusters
- Change the current primary cluster to secondary cluster with inactive writer instance
- Promote one of the secondary cluster to primary cluster
- In Route 53, update all end points (Primary, Managelinks, Query, Mobility, audit, and backup) to route the traffic to new primary cluster
- Enable write operation
- Create non-primary clusters (Managelinks, Query, Audit, Backup and Mobility) in the new primary region.
- In Route 53, update all non-primary endpoints (Managelinks, Query, Mobility, audit, and backup) to point to new clusters
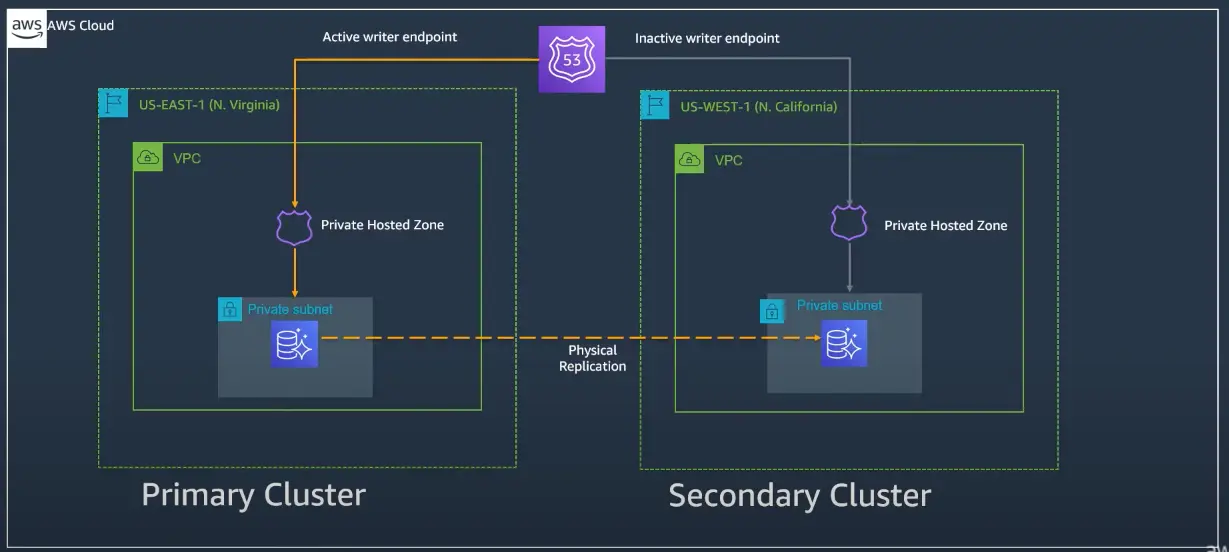
The replication topology will be maintained during this failover. The total down time (no write operations) will be between 5-6 minutes and it depends on the replication lag. If all traffic is routed through Route 53, the following solution can automate the planned failover process. All applications will be using a common url which is defined in the Router 53 to point to actual endpoint url of the database cluster. This means that the applications will never connect to the database using the actual database endpoints. All traffic will be routed through Route 53.

After completing the fail over, AWS Aurora Global Database will send an event to AWS Event bridge. Upon receiving the specific event, the event bridge will trigger a lambda, which will update the dns entries at Route 53 to point to the new endpoint.
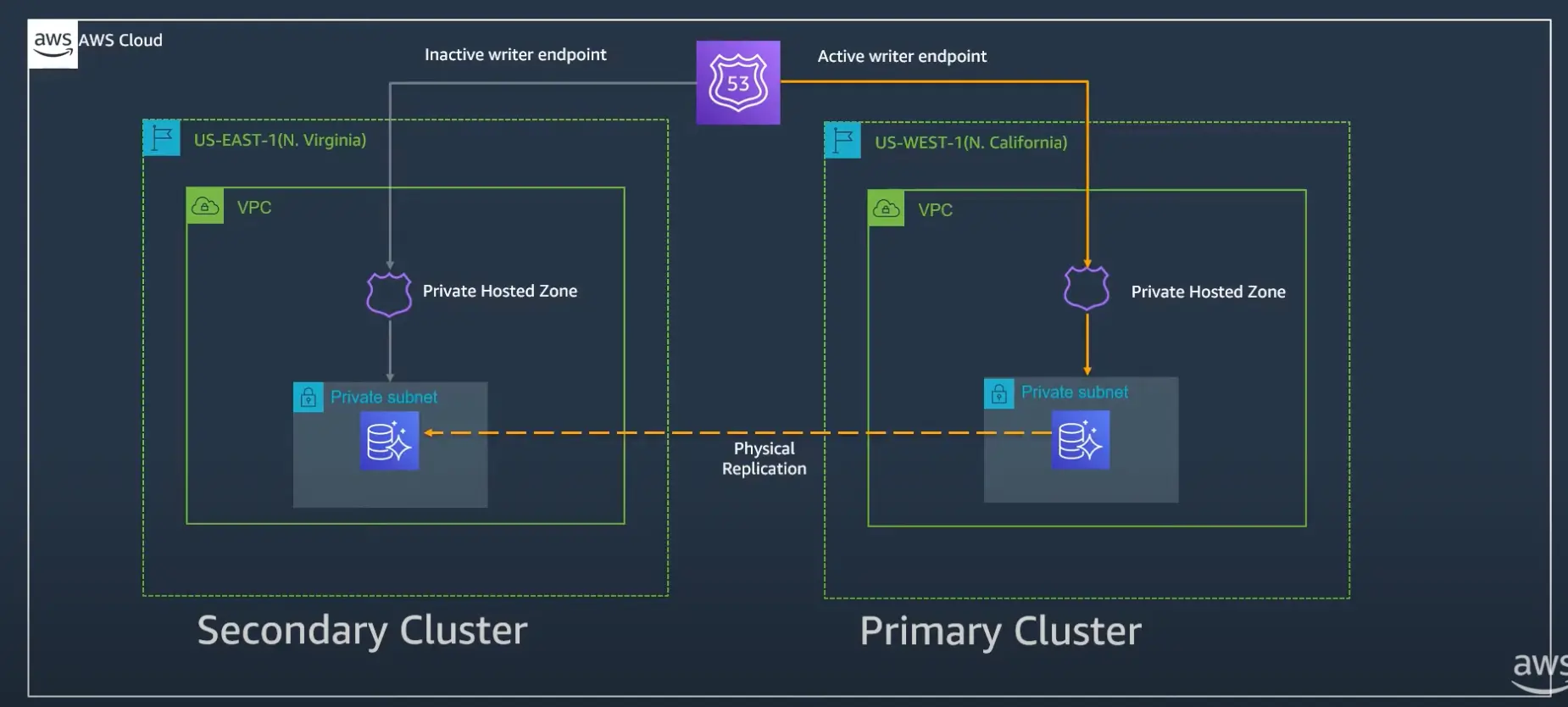
Unplanned failover
If the writer instance fails due to any reason (eg: database crash or natural disaster), AWS Aurora database promotes another reader instance within the region to the writer instance. However, if the entire region becomes unavailable, we need to detach and promote one of the available secondary regions. Unplanned failover follows similar steps as planned failover except it will be triggered based on detach and promote event. After an unplanned failover, the Global Database configuration will be deleted. The promoted cluster will process all read and write requests as a stand alone cluster. Early detection of a regional failure is critical to unplanned failover. “AuroraGlobalDBReplicationLag” is a good metric to identify a regional outage in the early stage. In addition, we will explore the option of using Canary based health checks to detect the issue proactively and trigger an automated detach and promote workflow to minimize the potential downtime.
Metrics and alarming
Create alarms for both reader and writer instances in each region based on the following metrics. Alarms will be triggered based on current rules in production and will be adjusted by monitoring the production traffic after migrating to Aurora Global database. If the metric is new, then the threshold will be set based on the initial traffic pattern.
- AuroraReplicaLag
- CPUUtilization
- DatabaseConnections
- DMLLatency
- FreeableMemory
- FreeLocalStorage
- LoginFailures
- NetworkThroughput
- Queries
- SelectLatency
- AuroraGlobalDBReplicationLag