- Published on
Set Predicting Algorithm
Table of Contents
Abstract
The blog is concerned with the method of prediction of a set of numbers using generic data processing and neural network. The data processing is generalized and can be followed up by any suitable prediction model for your use case. Each input or output is not an image or a sequence, but a set: an unordered collection of multiple objects(represented by numbers in the blog), each object described by a feature vector. Their unordered nature makes them suitable for modeling a wide variety of data, ranging from objects in images to point clouds to graphs. Deep learning has recently shown great success on other types of structured data, so we aim to build the necessary structures for sets by preprocessing data and feeding it into deep neural networks. The first focus of this blog is the learning of better set representations (sets as input) by data preprocessing. The second focus of this blog is the prediction of sets in a progressive manner. Current approaches do not take the unordered nature of sets into account properly.
Introduction
Problem Statement
We have taken a simple problem statement that can be further extended and converted to complex ones, or many complex set predicting problems can be reduced to this:

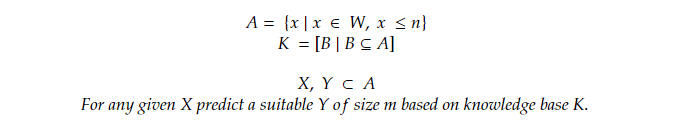
Given a sample space of numbers from 0 to n (n is a positive whole number) and a knowledge base (K) that is a list of a random subset from this sample space. So for every set X predict a suitable set Y of size m based on K.
Objective
To be able to predict a suitable set of numbers for any given set based on the knowledge base Of a list of sets of numbers from 0 to n. Also to conclude this blog discuss potential future applications for sets predicting algorithm.
Theory
Sets in machine learning
Sets are collections of things without a natural ordering to them. They are a natural way of describing different kinds of data in the real world. There are many problems of interest to the machine learning community that can be described in terms of sets: predicting the set of objects in an image is known as object detection; Lidar scanners on self-driving cars produce a set of 3d points of their surroundings to find obstacles.
In this blog, we will focus on a specific type of machine learning method for working with sets: deep neural networks and we would use a set of numbers as the input.
Basic of the model

First, let us be clear with what we mean when we talk about sets. In essence, sets are unordered collections of entities or elements. These entities can be objects, people, atoms, symbols, and so on. Since we are working in machine learning, it is useful to describe each entity in the set with a feature vector.
Let's say we have sample space as [0,10] the knowledge base will look like
{[1,2,3],[3,4],[5,6,7,8],[1,6,2],[2,3],[9,10,2,8,7], . . .}
We want to convert this into a feature vector that can justify the unordered relation between all elements of each subset. Since the elements in the set typically correspond to real-world things, it does not make much practical sense to talk about infinitely many entities. So, the sets we work with will always have a finite number of elements in them, for this example, it's 10.
Training model and Predictions
Now that we know how sets are stored, let us take a look at how such sets can be encoded into a feature vector. We want to build a neural network that can take a set of feature vectors as input and produce a feature vector representation of a predicted set, which can be then decoded by a decoder into the final prediction.

Set encoders
Set encoders task would be to convert an input set into a set of input feature vectors and their respective output while maintaining the unordered nature of the sets. That means the encoding function will follow:
𝑓 ( [1, 2, 3]) = 𝑓 ( [2, 3, 1]) = 𝑓 ( [3, 2, 1]) = . . .,
Let's take another example where we have sample space of 4 and the knowledge base is:
[1,2,3],[3,4],[1,2]

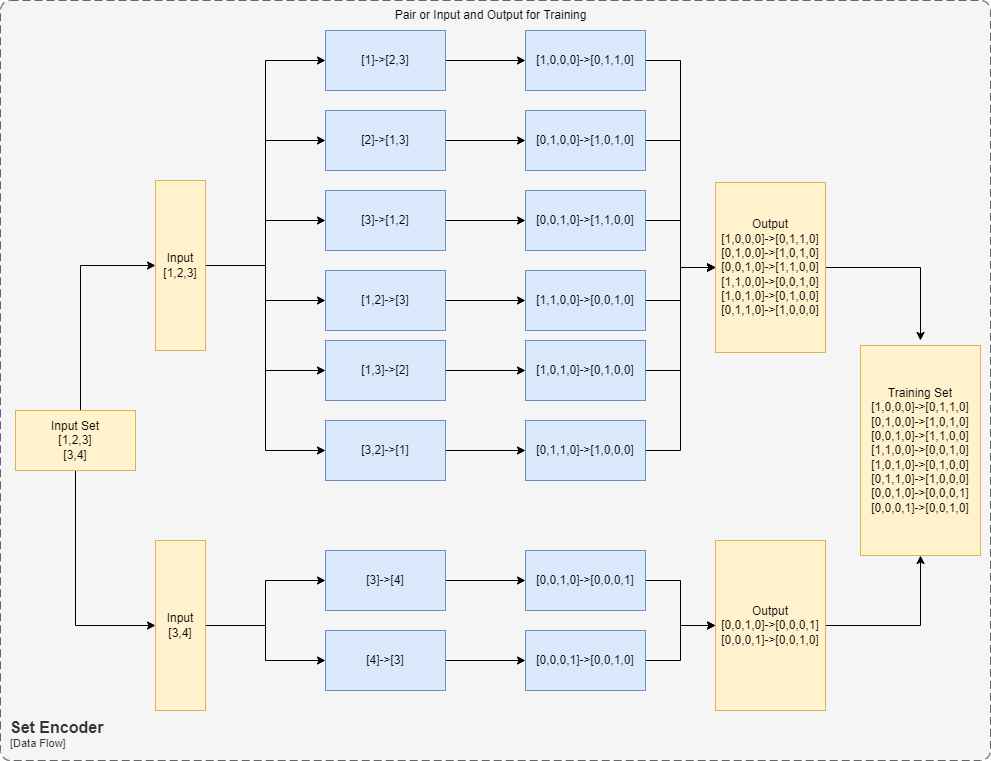
At this point, we have our training set and could just feed in a traditional neural network details which are discussed below.
Neural Network
We will be using a simple neural network to solve this multi-class classification problem. Each n-dimensional input vector maps to another n-dimensional vector we formed from set encoder, this can be trained on a fully connected neural network with n nodes in both input and output layers.
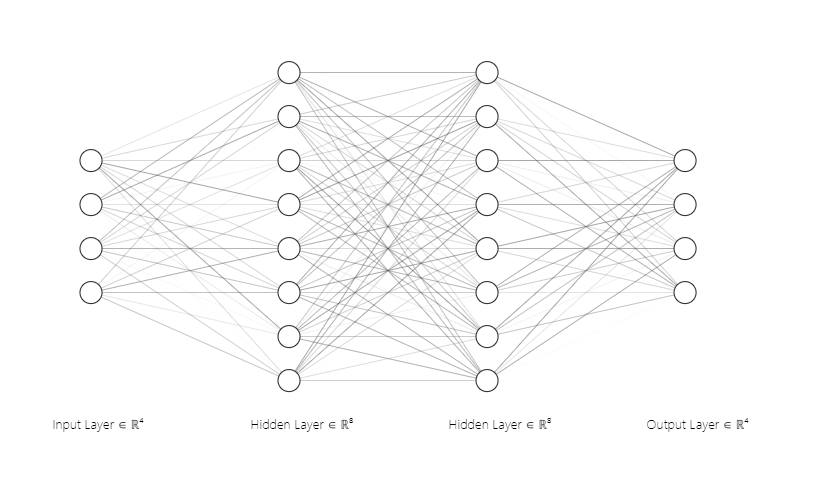
Now, we can set up the sizes of our neural network, first, below is the neural network we want to put together. Below initializations, ensure the above network is achieved. So, now you are asking “What are reasonable numbers to set these to?”
- Input layer = set to the size of the dimensions
- Hidden layers = set to input_layer * 2
- Activators = relu for input / hidden layers and hard_sigmoid for last layer.
- Loss function = binary_crossentropy
- Optimizer = Adam with learning_rate: 0.001
- Metrics = binary_accuracy
- Output layer = set to the size of the labels of Y. In our case, this is 7 categories
These fit best for the dataset we have discussed below, but can be tweaked based on the problem and dataset.

Set Decoder
This is a fairly simple component that maps the output vector to the corresponding set of numbers. The output vector from the neural network will be the probabilities of each number based on, which element is best suited next in the set.
The decoder will take in the m i.e. the number of elements to predict (refer to problem statement for more context). It will select the m highest probability numbers and return those as the model predictions.
Prediction
Now we have a fully trained neural network, so how to use it to predict set elements. For this, we would have an input of the current set. This we need to convert into a feature vector, which will have 1 for all the numbers present in the set and 0 for others. This is what was done in the first part of set encoder. This vector once submitted to neural network, will give out a similar n-dimensional vector containing the probabilities of each number to be in the set next. Based on these probabilities the set decoder selects the m highest probabilities and dereference the numbers from the n-dimensional probability vector. These numbers become the predictions of the model.
Live Demo
For complete code you can visit github and try it on google colab: click here.
We want to predict the items a person is most likely to buy if he has added some x items into the cart. For this, we have a dataset that consists of cart items purchased by different persons in a shopping store.
Get shopping cart data
from google.colab import auth
import gspread
from google.auth import default
creds, _ = default()
gc = gspread.authorize(creds)
auth.authenticate_user()
wb = gc.open_by_url('https://docs.google.com/spreadsheets/d/1bRsu9oH3N5A6N7rGFPZ3pngCvwfuHw4_57V_YCHUj38/edit?usp=sharing')
sheet = wb.worksheet('shopping_cart')
raw_data = sheet.get_all_values()
df = pd.DataFrame(raw_data)
Tokenizing Data
We are tokenizing the items bought by customers into serial number tokens. So that this problem statement can be converted into the one discussed above.
data=[]
for inner in raw_data:
tmp = []
for str in inner:
if str != '':
tmp.append(str)
data.append(tmp)
tok_data = {y for x in data for y in x}
tokenizer = Tokenizer(filters='!"#$%&()*+,-./:;<=>?@[\\]^`{|}~\t\n',split='#')
#tokenizer = Tokenizer()
tokenizer.fit_on_texts(tok_data)
sequences =tokenizer.texts_to_sequences(data)
random.shuffle(sequences)
sequences = list(filter(None, sequences))
Preparing data for training
This is the code for the set encoder talked about above.
FEATURE_SET_SIZE = max(list(map(max, *sequences)))+2
input= []
output=[]
for row in sequences:
row_len = len(row)
for subset in subset_list(row_len):
input_sum = np.zeros(FEATURE_SET_SIZE, dtype=int)
output_sum = np.zeros(FEATURE_SET_SIZE, dtype=int)
for index in range(row_len):
if index in subset:
input_sum = [a + b for a, b in zip(input_sum, binarize(row[index]))]
else:
output_sum = [a + b for a, b in zip(output_sum, binarize(row[index]))]
input.append(input_sum)
output.append(output_sum)
input= np.array(input)
output = np.array(output)
input, test_input= split_list(input)
output, test_output= split_list(output)
Training model
model = Sequential()
model.add(Dense(FEATURE_SET_SIZE*2, activation='relu', input_dim=FEATURE_SET_SIZE))
model.add(Dropout(0.5))
model.add(Dense(FEATURE_SET_SIZE*2, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(FEATURE_SET_SIZE, activation=keras.activations.hard_sigmoid))
model.compile(loss='binary_crossentropy',optimizer=adam_v2.Adam(learning_rate=0.001), metrics=["binary_accuracy"])
model.fit(input,output,epochs=3,batch_size=50)
Testing model
score= model.evaluate(test_input,test_output,batch_size=50)
Prediction
Time to test, with custom input and predict top m most popular items a person can buy if he buy x set of item
x=["soda"]
m=3
test_list = tokenizer.texts_to_sequences(x)
tmp_input=[]
tmp_input.append(prepare_data(test_list))
tmp_input.append(prepare_data(([1])))
tmp_input= np.array(tmp_input)
result = model.predict(tmp_input,batch_size=None,verbose=0,steps=None)
indices = (-result[0]).argsort()[:]
predicted_token = [x for x in indices if x not in test_list and x!= 0][:m]
final_prediction = tokenizer.sequences_to_texts([predicted_token])
final_prediction
## Output: ['pastry canned beer whole milk']
x=["soda", "canned beer"]
## Output: ['specialty chocolate sausage frankfurter']
Summary
In this blog, we discovered how to develop a neural network to predict a suitable set of numbers for any given set based on the knowledge base Of a list of sets of numbers, by honoring the unordered nature of sets. We also discussed a few practical scenarios in which this problem statement can be extended.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.